




Beschreibung
🧠 Run large language models entirely on-device in Unreal Engine - for AI-driven NPCs, dynamic dialogues, and offline chatbots. Cross-platform, powered by llama.cpp
Run GGUF-format LLMs (Llama, Mistral, Phi, Gemma, Qwen, TinyLlama, and more) directly within your Unreal Engine project with no internet connection, no API keys, and no cloud dependencies at runtime. The plugin wraps llama.cpp with a full Blueprint and C++ API, load models, send messages, and receive token-by-token streamed responses, all on a background thread with game-thread callbacks.
Quick links:
💬 Discord support chat
📌 Plugin Support & Custom Development: [email protected] (tailored solutions for teams & organizations)
Key features:
🎯 Core Capabilities:
Complete offline inference: no cloud services or API keys at runtime
GGUF model support: load any GGUF-format model (Llama, Mistral, Phi, Gemma, Qwen, etc.)
Up-to-date llama.cpp: updated regularly on Fab to keep pace with llama.cpp releases, so the latest GGUF model formats are always supported
GPU acceleration: Vulkan on Windows and Linux, Metal on Mac and iOS, optimized CPU + intrinsics on Android and Meta Quest
Cross-platform: Windows, Mac, Linux, Android (including Meta Quest), iOS
⚡ Model Loading & Management:
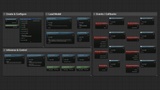
Load by model name with a dropdown selector in Blueprints
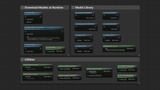
Download from URL and load automatically: skips download if the model already exists on disk
Download-only mode for pre-caching models (e.g. on a loading screen or settings menu)
Editor model manager: browse a built-in catalog, download, import custom GGUF files, delete, and test models directly in project settings
🗣️ Inference & Conversation:
Token-by-token streaming: receive each token as it generates for real-time display
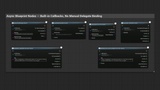
Configurable inference parameters: temperature, Top-P, Top-K, repeat penalty, GPU layer offloading, context size, seed, thread count, and system prompt
Conversation management: multi-turn conversations with context reset, save/load to disk, in-memory snapshots, and automatic summarization for long-running chats
Generation cancellation at any time
🛠️ Development Features:
Full Blueprint and C++ API with async nodes and delegate-based callbacks
Model library functions for querying available models, checking disk presence, retrieving metadata
Automatic packaging: models ship with your project via NonUFS staging with no manual configuration
Comprehensive error handling with descriptive error codes
🎮 Perfect for:
NPC dialogue and dynamic conversations
In-game AI assistants and companions
Procedural content generation (quests, lore, item descriptions)
Voice-driven gameplay workflows (paired with Runtime Speech Recognizer and Runtime Text To Speech)
Offline chatbot interfaces
Educational and training applications
Privacy-sensitive deployments with no data leaving the device
🌟 Compatible plugins:
Runtime AI Chatbot Integrator: cloud-based LLM APIs (OpenAI, etc)
Runtime Text To Speech: offline TTS for speaking LLM responses
Runtime Speech Recognizer: offline speech-to-text for voice input
Runtime MetaHuman Lip Sync: real-time lip sync driven by TTS output
Runtime Audio Importer: runtime audio processing and playback